A385-基于机器学习的医学图像检测小作业
导出时间:2025/12/5 16:10:17
题目二:医学图像检测
数据文件
- 训练数据集(2类,共1639幅图像):以jpg格式存储在2-MedImage-TrainSet.zip。
- 测试数据集(2类,共250幅图像):以jpg格式存储在2-MedImage-TestSet.zip。
每个数据集中,以disease开头的文件为患病图像,以normal开头的文件为无病图像。
性能指标
最基本的指标是测试集上的分类准确度。考虑到患病与无病样本数量不均等,且两种误判(无病判断成患病、患病判断成无病)带来的风险不同,因此为了全面反映分类器性能,还可以给出精确率、AUC、ROC曲线(指标函数已给,在ROC文件夹中,代码使用详细见instruction.txt)或其他指标。
这里使用三种机器学习模型: SVM模型 逻辑回归模型 随机森林模型 根据类别不平衡设置类别权重
数据集统计:
训练集: 1639 个样本
正常: 993
患病: 646
测试集: 250 个样本
正常: 150
患病: 100
==================================================
开始训练 LOGISTIC 模型...
==================================================
模型训练完成!
==================================================
模型评估结果:
==================================================
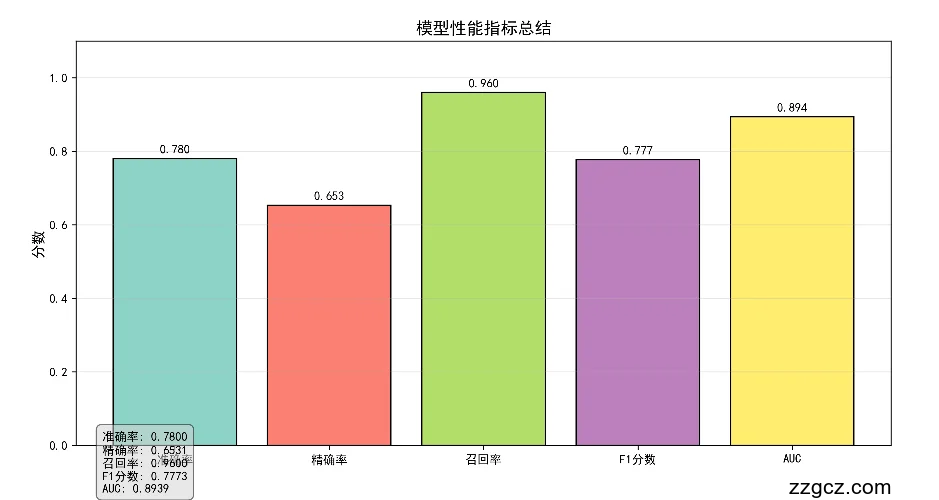
测试集准确率: 0.7800
精确率 (Precision): 0.6531
召回率 (Recall): 0.9600
F1分数: 0.7773
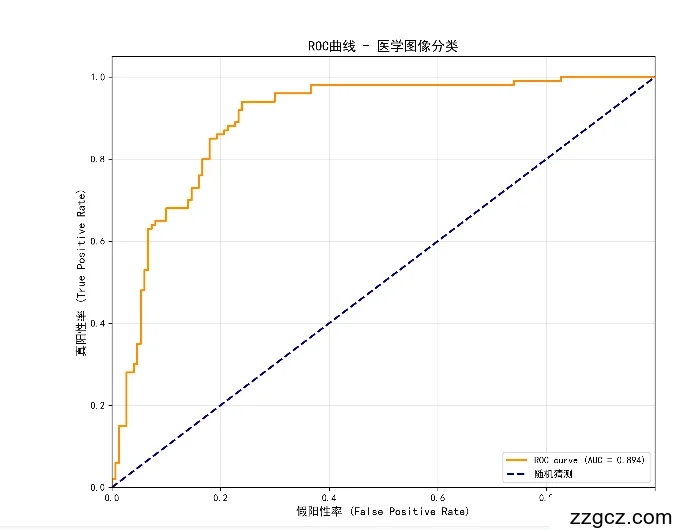
AUC: 0.8939
分类报告:
precision recall f1-score support
normal 0.96 0.66 0.78 150
disease 0.65 0.96 0.78 100
accuracy 0.78 250
macro avg 0.81 0.81 0.78 250
weighted avg 0.84 0.78 0.78 250
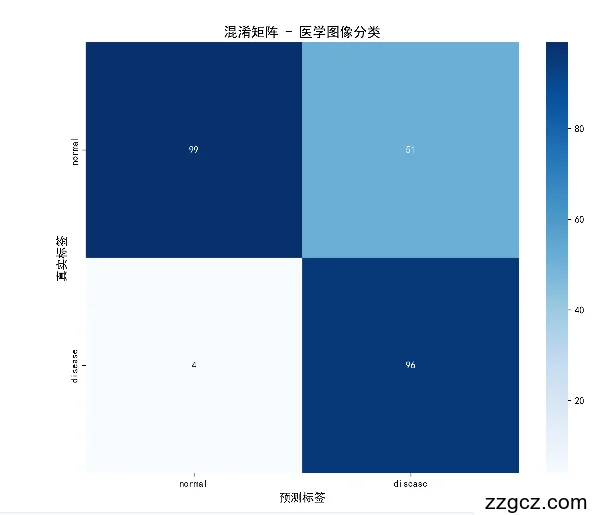
混淆矩阵:
[[99 51]
[ 4 96]]
==================================================
生成可视化结果...
==================================================
ROC曲线已保存到: roc_curve.png
混淆矩阵已保存到: confusion_matrix.png
指标总结图已保存到: metrics_summary.png
模型已保存到: medical_image_classifier.pkl
==================================================
误判风险分析:
==================================================
假阳性 (正常→患病): 51 个样本
假阴性 (患病→正常): 4 个样本
总误判数: 55 个样本
假阳性率: 0.3400
假阴性率: 0.0400
风险分析:
- 假阳性 (误诊): 可能导致不必要的进一步检查、治疗和心理压力
- 假阴性 (漏诊): 可能延误治疗,导致病情恶化
 |  |